State capacity and Mexico’s COVID-19 response
Managing or mitigating risk often depends on asking relevant questions and on having timely and reliable information that can measure the relative frequency of catastrophic events one is seeking to avoid. Whether Mexico can contain the SAR-CoV-2 virus infection and the tragedies of countless deaths associated with it remains a highly controversial question. From the very beginning the strategy followed by the health authorities in Mexico was unusual, due to the mixed messages by the President regarding the severity of the epidemic; a generalized perception that the federal government was overconfident in its reliance on its sentinel epidemiological surveillance model; and the fact that too little testing was being done in order to really know how the COVID-19 disease evolved over the territory. Arguments as to whether the public response of the federal government in delaying the closing of economic activity for far too long, or reopening the social distancing measures all too soon, should be settled on the basis of evidence. Although researchers have much work to do in this front, quite a bit of data is already available, and goes a long way in providing insight into what the government seems to have done well, where it has failed, and the momentous challenges ahead.
As the Federal government has started to move into a gradual process of opening up economic activity, many observers worry that Mexico has not yet experienced the peak of the epidemic. The data used to know this comes from Mexican official sources. Mexican health professionals produce this data, working within specific organizations (clinics and hospitals, registered by the state through a unique code identifying every health establishment) that are part of larger state institutions, within the national public health system and the welfare state. Understanding the evolution of the epidemic hence requires some better understanding on how state institutions are responding in a more or less effective manner not just to the public health challenge but also to the governance imperative of generating knowledge about the process. One of the crucial features of any effective bureaucracy is its capacity to keep record and track case statistics, and to learn from the information thus produced about its own relative performance.
Since April 14, the Mexican government has been publicly releasing data providing detailed information regarding all respiratory disease patients and COVID-19 tests administered to those seeking care in the national health system (including both public and private hospitals and clinics). The database is updated daily by the federal health officials (a repository of every released dataset can be found in the Secretaría de Salud). As of June 30 the public dataset includes 581,576 cases that form the basis of study for the national public health strategy facing the pandemic. Some excellent exercises of visualization have already been made with this data, seeking to determine whether the curve has “flattened”. This data is, thus far, the best available information on the severity of the epidemic in Mexico. There is no reason to believe that the released data is any different from the data the Federal health authorities has been using to build and assess their own epidemiological models. There are some inconsistencies in the way patients are recorded, more noticeable as new releases of the dataset have been published. In particular, some patients seem to disappear from the dataset. But these anomalies seem to be mostly a consequence of registration and administrative procedures followed when updating the records, rather than a purposeful effort by Mexican health authorities to hide or withhold information. The dataset does not include, due to the way it is constructed, any infected individuals who do not seek care. That is, given the relative paucity of testing in Mexico, the dataset contains very few asymptomatic cases. It may include duplicates of the same patient to whom more than one test has been performed. And some patients may have been lost due to administrative error as the records are updated. But the dataset offers a comprehensive picture of the evolution and trends not just of the COVID-19 epidemic, but of the fate of all patients seeking care for respiratory ailments and the differential performance of the national health institutions.
A careful analysis of the available data suggests one major finding (albeit provisional, pending further research) and a series of questions. The finding is about the risks and the prevalence of infection: despite doubling of the number of tests during the past month, the positivity rate in Mexico remains much higher than virtually anywhere in the world, almost at 50 percent. Coupled with the fact that many patients with respiratory diseases, but who did not test positive to COVID-19, are dying suggests that the circulation of the SAR-CoV-2 virus in Mexico is more widespread than officially recognized. Mexico’s opening is probably riskier than the health authorities want to acknowledge. Major questions emerge about the differential performance by health institutions to the challenge of saving lives: IMSS, INSABI, ISSSTE, municipal and University hospitals and clinics, and private health providers exhibit widely different case fatality rates (CFR). This is probably due to a complex combination of factors, including a difference in the intensity of the disease among the patients they serve (IMSS probably treats the most serious cases), variations in associated comorbidity risks, the uneven territorial coverage of each health institution, and the underlying socioeconomic status of patients visiting their hospitals and clinics (private establishments treat richer people). Understanding the reasons behind these institutional differences is crucial for a better public health response to the disease in the coming months. And to be honest, very little seems to be known about those differences.
The epidemic in Mexico is severe. This is not indicated by the official number of cases, but by the mortality figures. In the absence of a better indicator, mortality risk can be measured by what is known as the Case Fatality Rate (CFR). It is important to understand that this is not a proper mortality rate. It a rather imperfect measure of risk, due to it denominator, namely the number of patients seeking care. Instead of knowing about deaths among all infected individuals, or the general population, the CFR tells us about the share of individuals who have a probability of dying, among those who are counted as cases by the health system (and become part of the official database). The ratio does indicate the highest bound of possible mortality. But there is no reason to assume that, given the paucity of testing in Mexico, it is correlated with the true quantity of interest, the Infection Fatality Rate (IFR).
The CDC defines Symptomatic CFR as follows:
Symptomatic Case Fatality Ratio: The number of symptomatic individuals who die of the disease among all individuals experiencing symptoms from the infection. This parameter is not necessarily equivalent to the number of reported deaths per reported cases, because many cases and deaths are never confirmed to be COVID-19, and there is a lag in time between when people are infected and when they die. This parameter reflects the existing standard of care and may be affected by the introduction of new therapeutics.
According to the Mexican official figures a very large number of patients, 27,769 as of June 30, had already died from COVID-19. There are an additional 9,355 patients who have died from respiratory ailments, even though tested negative (or had pending results) for COVID-19. The number keeps on growing even though the CFR is declining. The total CFR, calculated with the full dataset released on June 30 (regardless of whether the patient test resulted positive, pending or negative to COVID-19) is at 6.38 percent. The CFR for patients that yielded negative and pending results is 2.63; while the CFR for the positive confirmed cases is 12.28. In the graph below one can see that the evolution of the CFR of Mexico over time remained at very high levels during April (the graph assigns the death to the day when the patient was registered as admitted for treatment) but has been going down during May and June. Even as it has declined, it still remains above 10 percent (the graph does not include data for the last two weeks, because that information is changing significantly every day, due to reporting delays).
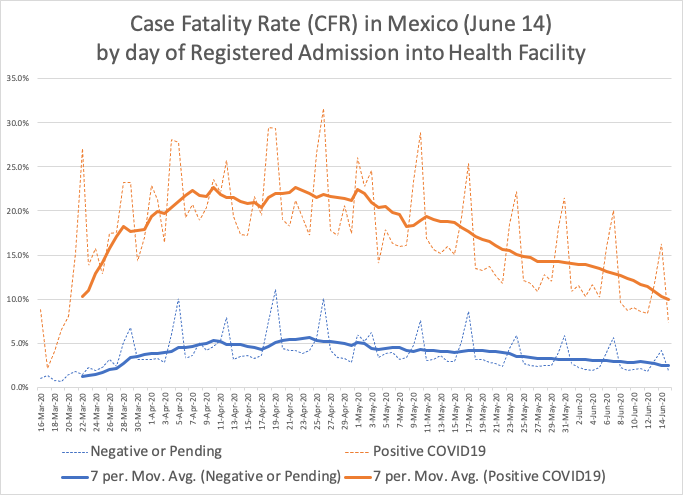
Many patients in Mexico die from respiratory diseases without confirmed COVID-19 laboratory test results (the blue line in the graph). These patients exhibit a vary large CFR, that reached almost 5 percent at its peak, well above a typical influenza illness. Although we know that the specificity of tests available is quite high, it is quite possible that the sensitivity (the possibility of false negatives) of COVID-19 testing in Mexico may be lower than its theoretical value. False negatives would be attributable to many reasons, including the quality of the procedures for specimen collection, their correct preservation to be usable, as well as the laboratory processes. Hence it is important to include in the analysis all deaths arising from patients seeking care with acute respiratory symptoms, even those that show pending or negative results.
A relatively high CFR is to be expected in Mexico given that the national strategy involved a strict rationing of tests. The dataset only counts deaths registered through the capacity of health organizations to keep records of them. As in other countries, excess mortality will eventually probably show a higher death toll, arising from patients that may be dying at home, without access to the health system, or that may be misclassified as caused by other diseases. Due to the incapacity of Mexican civil registries to produce more timely vital registration mortality statistics, we will only learn about that excess mortality when the records from death certificates are collected, processed and aggregated. Vital statistics in Mexico have usually taken relevant authorities including INEGI, the National Statistics Office, about two years to be fully compiled. But even with such underestimation, it is likely that, in most areas of the country, the Mexican official data collected by the health system is more or less complete.
A CFR is a difficult indicator to interpret because it depends as much on actual mortality as on the prevalence of testing. But to understand more about how testing has been carried out in Mexico, one can explore something called the positivity level (the share of tests yielding positive results), and, in particular, how that indicator has changed as more tests have been performed. The level of positivity in the full dataset of patients under study in Mexico is 38.9 percent (as of June 30). This number is very large when compared to any available international indicators. The fact that the positivity rate is high suggests that a many asymptomatic patients may be present in the general population.
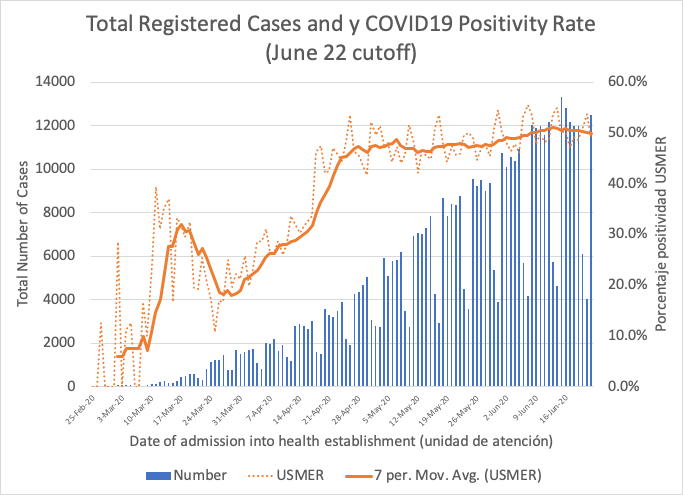
In order to understand the relationship between the CFR and the positivity rate, it is useful to know something else about how the dataset of patients under study is generated. The official dataset of patients tested for COVID-19 in Mexico comes from two distinct bureaucratic processes. The first one produces a relatively systematic sample, collected through the 475 USMER medical establishments (Unidades de Salud Monitoras de Enfermedades Respiratorias). This system establishes testing for ambulatory patients with mild symptoms, within the epidemiological surveillance system (SISVEFLU, now called SISVER, which was established after the 2009 H1N1 pandemic). Those protocols of epidemiological surveillance are what has been referred to as the “sentinel” system. A test is collected for every tenth patient, regardless of the seriousness of symptoms. The patient does need, however, to be been seeking care for some respiratory infection, and show signs of cough, fever or headache. In the case of serious acute respiratory infections, accompanied by difficulty breathing (Infección Respiratoria Aguda Grave, IRAG), the system establishes that all patients in USMER clinics must be tested. A third of the official dataset (35.7 percent) comes from USMER hospitals and clinics. For the rest of medical establishments in the country, a patient is only tested if they fulfill the definition of a suspicious COVID-19 viral respiratory disease case, according to a previously established algorithm.
Although USMER data is not exactly a random sample, it includes tests for both patients who are seriously ill and some patients that are not. The graph below shows the evolution of positivity in Mexico for USMER patients, together with the total number of tests or registered samples (for the full dataset). Testing has been steadily increasing, as can be seen by the climb in the bars. The positivity rate kept climbing up during much of the month of April, to finally stabilize somewhere between 40 and 50 percent during May. What is rather striking about the Mexican data is that as daily testing more than doubled during the month of May, the positivity rate did not budge, even in USMER clinics and hospitals that were testing milder cases.
Understanding the capacity to register patients and their characteristics. All health providers in Mexico must fill out a format called “Formato de Estudio de Caso Sospechoso de Enfermedad Respiratoria Viral”, which is the source of the information that the government has released publicly. The public version of the database includes most of the information from that format. A dictionary of all the released variables was released with the dataset. As ethics in research require, it contains no personal identifiers. The public dataset does not include some medical indicators, such as the classification of symptoms and some treatment variables, especially regarding the use of antivirals. For reasons that are not altogether clear, the public database is missing three sociodemographic characteristics that are explicitly requested in the format: 1) the self-ascription as a member of an indigenous community (the database does include information on linguistic self identification, but self-adscription is a much broader, and perhaps more useful definition of ethnicity); occupation (in the format this is an open-ended question allowing for free-form answers, so the absence of this information may be an issue of coding too many different answers); and whether the patient is a teacher (¿pertenece a alguna institución educativa?).
The format records information on the evolution and release of the patient, but this information is not released publicly in its entirety. The reasons for withholding such information are not altogether clear. This is the most obvious shortcoming of the public database in that it does not include the information on the release date, and whether the release (alta) was due to improvement (mejoría), cure (curación), voluntary release, or transfer. Given that health providers are filling out this information, a potential reason to not allow researchers to know about it could be related to fears about what it may reveal regarding the quality of care. This might be the same reason why the data on signs and symptoms and treatment is not publicly available either. However, some of the information on the evolution of the patient is publicly released: whether a patient was moved to an Intensive Care Unit (ICU), was intubated, or was diagnosed by the health provider as pneumonia. It is not completely clear whether the timing of these interventions is entered at the time of admission, updated during the course of treatment, or as the patient is released from a health facility (or dies).
This is related to a more general problem regarding the timeliness of the data. It is not clear when cases are added to the database and what determines the public release. There are significant delays in reporting, and these delays vary across reporting health institutions and states. This affects any analysis of the latest few weeks in the dataset. Often deaths that may have occurred many days earlier show up in the dataset with a significant lag in their release. The most systematic analysis of this issue, as far as I am aware, has been done by Jorge Andrés Castañeda and Sebastian Garrido. Delays in reporting do not seem to respond to a purposeful effort to hide information, but rather to the limits in the capacity of each health institutions to provide timely information.
It is possible that the many serious cases are not being added to the dataset until after the clinics or hospitals have resolved them, either as discharges or deaths. There are also some important differences in the way each health institution registers data. The most obvious difference is found in the intubated patients reported by IMSS. It seems that this institution was not providing such information until the most recent releases (and even there the numbers of intubated patients remain too low to be correct). Much of the IMSS data seems to be updated over the weekends. And there are some unusual dips in test on Saturday and Sunday, which suggest that the date of admission is not exactly the day when the patient seeks care, but the day when it is recorded by the health provider, with weekends lagging behind (recorded deaths and the day of onset of symptoms, in contrast, are evenly distributed every day of the week).
CFR differences according to health establishment. Having established that the official data comes from the institutions that provide public (and private) health in Mexico, and it is clear that the patient records are subject to differences in administrative processes, quality of care and capacity between and within those organizations. This is not the place to explain the complexity of the Mexican health system, but in an extreme simplification one can think of it being composed by three pillars. The first one is based on the Instituto Mexicano del Seguro Social (IMSS), where social security benefits are provided, including health, to all formal workers and their families on the basis of the contributions they and the firms that employ them make to the national health system. IMSS also administers a very important system of clinics in rural areas, that are now labeled as part of the Bienestar system, which attend rural patients. Federal public sector employees, and many employees from the public sector in other levels of government have a similar coverage to IMSS, through the social security institute state employees, also funded through payroll taxes, called ISSSTE. Members of IMSS and ISSSTE (plus some other institutions for specific employees, including the oil workers in PEMEX and the Armed Forces and the Navy) are what is usually referred to as derechohabientes, right-holders, to health services.
The second pillar is another public health institution, which provides care to non derechohabientes. This care is provided through what used to be the federal health SSA clinics, then called Seguro Popular clinics, and now labeled as INSABI, variously administered by the federal or the state levels of government. There are also various public health establishments that may be variously run by the Red Cross, state or municipal governments and some University hospitals. For an account of the Mexican health system that focuses mostly on the reforms to Seguro Popular, see the book by Laura Flamand and Carlos Moreno Jaimes.
For wealthier Mexicans there is also a third pillar, a system of private health establishments, which provides care on the basis of private health insurance. Although those patients can usually make use of IMSS because they are employed in the formal economy, they prefer to use the private institutions.
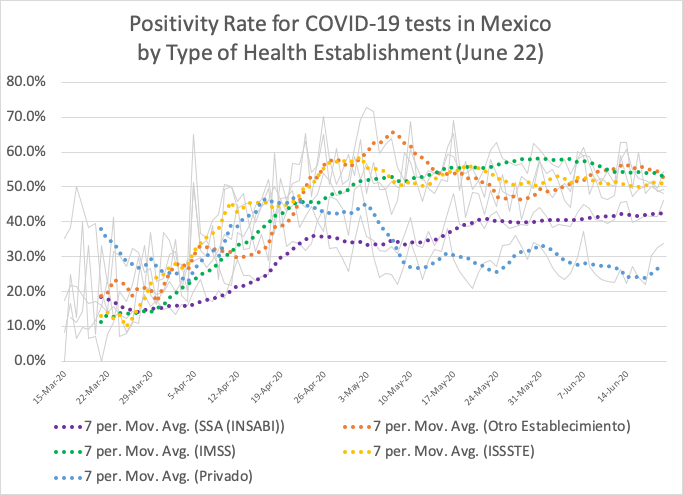
The positivity rate can thus be analyzed separating the various institutions that report cases. It is important to note that patients cared by each institution are different in their socio-demographic composition. Institutional capacity to deal with serious illness may also vary widely across providers, particularly cases that may require hospitalization. Hence there could be good reasons for positivity rates to not be the same across institutions. But the graph above suggests that the pattern of stable positivity rates is observed for all public institutions. Only in the private clinics and hospitals is there a sharp decline in positivity, at around the first week of May. But the graph also suggests that the INSABI / SSA clinics are either testing in a different manner or caring for a different profile of patients as compared to the other public health institutions.

The same breakdown of the positivity rate by health establishment can be done for the CFR, keeping in mind that the patients cared by each institution may differ in their underlying socio-economic and health characteristics and be “selected” by different processes. The CFR by institution, shown as a 7 day moving average, suggests that patients cared at INSABI / SSA and private institutions are less likely to die. And while the patients cared by the social security institutes IMSS and ISSSTE were the drivers of the overall national trend, they both seem to have been reducing their CFR over the past month.
Quality of care. Some researchers and journalists have expressed concerns as to whether there have been changes over the course of time in the inclusion or exclusion of patients in the database, and whether some of them may have been duplicated, particularly if they had more than one test performed. It is possible to check for potential repeated patients by matching them on their date of admission, onset of symptoms and sociodemographic and clinical characteristics (with the same age, gender, co-morbidities, and living in the same municipality). There are less than five thousand cases that may be repeated patients, showing exactly identical characteristics. It is more difficult to know whether there have been inconsistencies over time in the registration of patients that disappear from prior releases of the dataset.
Given that the way in which health providers register the patients is not completely transparent, analyzing the timing of disease onset and death must be taken with a grain of salt. The Mexican database suggests a more severe disease dynamic in terms of its timing, as compared, for example, to US planning scenario parameters considered by the CDC. But one must be aware that the data registration methodologies may not be fully comparable. The arrival of patients seeking care is not too different in Mexico from what is reported for the US: 42.1 percent of the patients seek care after less than two days with symptoms, 47.1 percent within 3 to 7 days, and only 10.8 percent come to seek care after 8 or more days of symptoms.
However, the time to hospitalization in Mexico seems to be very short: the average patient, regardless of age, shows up as hospitalized 3.9 days from the onset of disease (standard deviation 3.5 days), while this figure is about seven days in the US. We do not know in the Mexican public data how many days patients remain hospitalized, nor how many days it takes for them to be transferred to an ICU, or whether they started in an ambulatory clinic and then were moved to a hospital (such information should be part of the modeling exercises being performed by Mexican scientists to estimate hospital bed and ICU demand).
In the US more than 20 percent of hospitalized patients are transferred to ICUs, and most of them (around 70 percent) receive mechanical ventilation. In Mexico the dataset registers only 8.3 percent of hospitalized patients as entering the ICU (regardless of whether they tested positive to COVID19 or not). Given these differences, the time from onset of the disease to death is about 15 days in the US, while in Mexico it is lower, at 10.5. Such comparisons may reflect important differences in the demographic profiles of both countries, but they are also likely to reflect differences related to the quality of care.
Correlates of CFR according to health establishment. It is possible to estimate through a statistical model the statistical patterns or correlates of the CFR. Such estimations should not be used for causal inference. They do not support any claims about the reasons why death is higher in some circumstances than others, or why some variables are associated (either positively or negatively) with the probability of death. They should be thought of as relatively sophisticated cross tabulations, or descriptive statistical tables, that highlight a complex and interrelated set of processes, by conditioning the cells of a tabulation on individual or aggregate level characteristics that can be kept constant. Finding a correlation in this type of data is no evidence of any causal relationship. This should be particularly clear when considering that intubation, hospital care in an ICU, or having a clinical diagnosis of pneumonia are all positively correlated with death. That should not be interpreted as meaning that those medical care interventions increase the likelihood of dying: the relationship reveals, instead, the very strong selection effects that must be present throughout this data. A patient only enters the sample if she is seeking care, and more seriously ill patients are more likely to require extraordinary measures, but they may still die, notwithstanding the care they receive.
Although more sophisticated statistical modeling choices are possible, logit models allow for a clear visualization of the main patterns and some indication of strong differential institutional performance across health providers. In contrast to an OLS model, a logit takes into account that the distribution of the dependent variable is dichotomous, taking only the value of 1 when there is a death and 0 otherwise. Since deaths are (fortunately) not so frequent, even among patients contracting COVID19, an OLS model does not fit well the characteristics of the distribution. Logit models provide coefficients in the form inverse exponentials of log odds ratios, which are very difficult to interpret. In order to help with interpretation, I provide graphs of the predicted values generated by the statistical model as probabilities of death under various scenarios given by specific independent variables. All the code needed to run the estimates and visualize the graphs (in STATA) is provided in this Github repository.
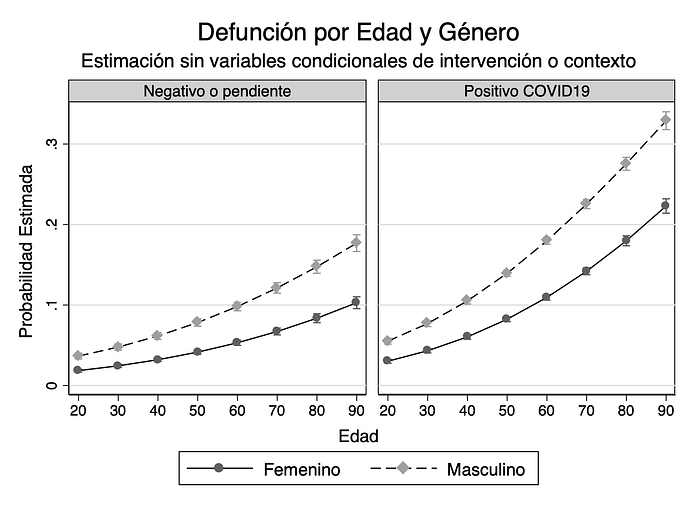
The simplest estimation one can make only uses two sociodemographic variables, namely age and gender, as correlates of the CFR. The simulation of those coefficients is presented in the first graph, which shows the predicted value of the probability of death depending on whether the COVID19 test result was negative (or pending) or positive. This is referred to as the unconditional model because it does not use any of the additional information about individual characteristics to provide a more precise comparison of age cohorts and gender. The left panel of the graph shows the estimated probability of death for the almost ten thousand patients who sought care for serious acute respiratory infections (Infección Respiratoria Aguda Grave, IRAG). It is possible that some of these deaths were actually going to show up as positive COVID-19 results, but perhaps occurred too soon (often on the same day of admission) leaving their testing pending.
A more complete model includes the state where the patient reported his or her residence, the health establishment where the patient receives treatment, and individual level characteristics (whether the patient speaks an indigenous language, is pregnant, had been in contact with patients testing positive to COVID-19, days since the onset of symptoms, and variables related to the medical intervention such as hospitalization, intensive care unit (ICU) admission, intubation and a pneumonia diagnosis). It is important to note that while the inclusion of hospitalization (instead of ambulatory care), being admitted in the ICU or intubation and having a clinical diagnosis of pneumonia all show a statistical association with a larger CFR, this does imply any causal relationship. These are straightforward selection effects.
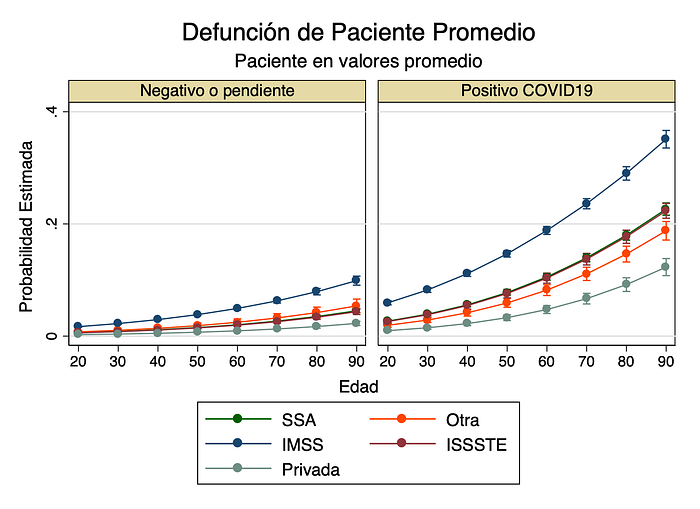
Perhaps the most important finding from the point of view of health governance is that there are institutional differences among the various health establishments in Mexico, particularly for IMSS and Private hospitals. This can be seen in the simulation above, that shows an average patient’s probability of death according to age, gender, and COVID-19 testing. The differences across health institutions may be driven in part by the aforementioned selection effects, given that the characteristics of patients being admitted into each type of health establishment may be quite different: richer, healthier and less serious cases may be arriving to private hospitals, while much more seriously ill, including uninsured patients may be treated in IMSS hospitals and clinics.
But it is possible that some of the differences among institutions are driven by the quality of care and the resources available in each type of institution. There seem to be also some differences in the quality of care among ISSSTE and other hospitals depending on whether the patient has tested positive to COVID19, and the degree of seriousness of the case. In complete epidemiological model co-morbidity factors will play an important role as a risk factor or a conditioning variable that may increase the likelihood of death. Those co-morbidities are by now rather well-know, not just from the case of Mexico but since the first analysis of data coming from China and Italy were done. It is clear that renal chronic conditions, immune diseases and diabetes might play an important role in how the disease affects different patients. Smoking does not show up as a significant factor affecting the risk of death.

I will not try to analyze the clinical aspects of comorbidity factors. Some studies have already started appearing, showing similar findings. What turns out to be rather striking is that there are differences in comorbidity according to the institutional makeup of health providers in Mexico. The graph above shows the estimated coefficients of what is commonly used in this type of studies, namely the excess risk as measured by the log odds ratio. Anything above 1 reflects a higher risk. Though the analysis is still relatively preliminary, there are some very notable differences in how patients may be more likely to die in IMSS establishments when they have renal chronic conditions, to note the most obvious difference. In INSABI / SSA hospitals and clinics, in turn, immunosupressed patients seem to be more likely to die than at the other institutions. Diabetes also displays a distinct higher co-morbidity risk in the case of ISSSTE patients, although given the smaller number of cases treated in that institution, the estimated coefficients are less precise, with a larger margin of error.
The point of this exercise is not to ascertain what the correct epidemiological model to study those co-morbidities may be or to accurately measure the relative magnitude of risks, but to note that various health institutions in Mexico seem to vary in how their patients are conditioning their survival to underlying health conditions. I am not competent to determine whether those differences are of a medical nature. But these findings, coupled with the differences in positivity rates, CFR and other variations observed in throughout the data suggest that we must start asking more questions related to the relative performance of health institutions in Mexico. Not just about how the data is recorded and transmitted, but of the underlying quality of care, and to identify limitations in resources or skills that may be overcome with timely action, and hence to save precious lives.
